
The creation of the matrix is the most intellectually challenging analysis that takes place during a scenario planning project, and also the most intuitive. Because of this dual nature, it is also the most difficult to teach because the processes used and combination of implicit and tacit knowledge. This blog post intends to make the implicit knowledge explicit, while identifying the areas of tacit knowledge, or ‘content-dependent practical knowledge’ (Thornton 2013), in use at the same time.
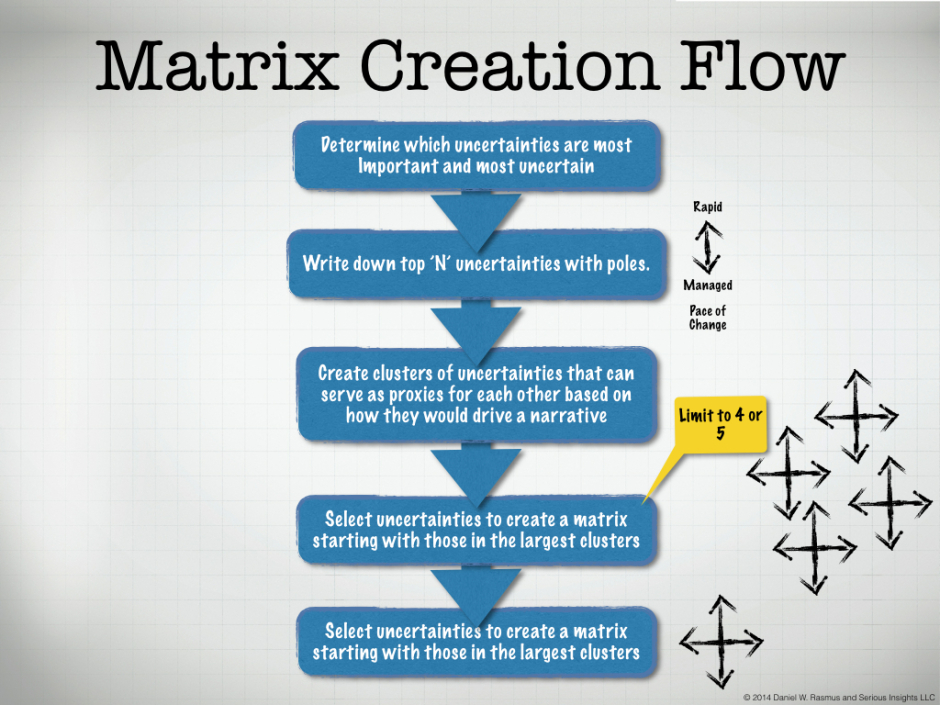
The matrix development process begins with the results of voting on important and critical uncertainties. From that vote several critically important uncertainties have risen to the top of the list.
Creating the Visual Uncertainty Space
Use a large sheet of paper, a whiteboard or other large surface and write down each uncertainty as a double-sided arrow with its name and labels for the poles.
This can be done on a computer using the drawing program of choice, but paper is preferred as playing with a drawing application can get in the way of the thinking while writing.
Do this for each of the uncertainties.
Identifying Convergence
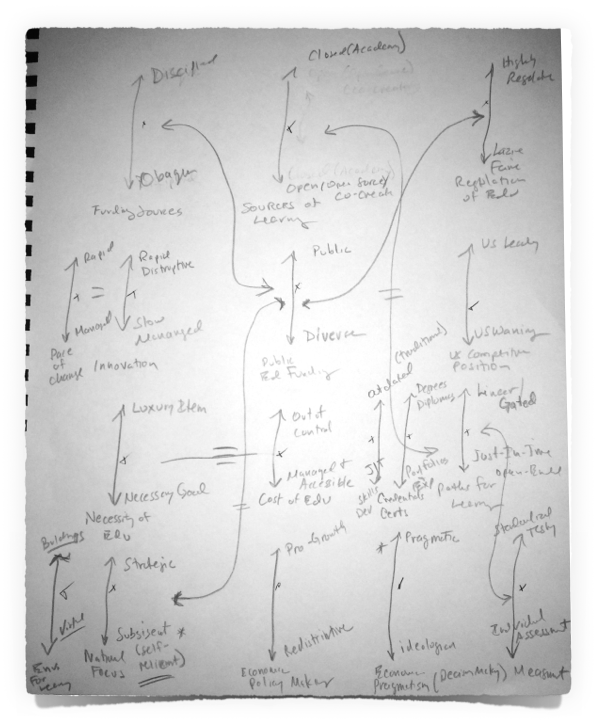
It will likely become clear that some of the uncertainties are very similar in terms of how they would drive the story, although they might be conceptually different areas. For instance, an uncertainty “Paths to Learning” with poles titles “Linear and Gated/Traditional” and “Just-in-Time/Open Ended” is narratively aligned with the uncertainty “Measurement,” with poles “Standardized Testing” and “Individual Assessment.” Although at the surface these are not necessarily related, any scenario story that is “traditional” will likely also include standardized testing.
From the storytelling standpoint, these can be thought of as proxies. Choose either one and the story is likely to veer along the same trajectory.
The University of Georgia work identified four additional proxies to complement the two already mentioned. One of them, “Sources of Learning,” with polls labeled “Closed/Academy” and “Open/Open Source/Co-Created” offers the biggest conceptual bucket for scenario development. In other words, it is the least narrow.
Two notes are important here:
- First: Why weren’t the similarities between uncertainties identified before the voting process, and the “duplicates” or “proxies” eliminated? A lengthy process of research and interviews generates uncertainties. Although it is possible to identify potential overlaps, and to reduce the number of uncertainties, that isn’t the goal of this exercise. This work focuses on trying to converge on a matrix with a strong set of narrative characteristics. The combination of uncertainties is not intended to discount or eliminate them from the stories but to understand the similarities in narrative drive. The subtle differences between the uncertainties will be seen as important when developing out the more detailed stories.
- Second: In this case, the idea of “standardized testing,” does not imply any particular form of test or even sponsor, and therefore, it does not limit what the team can imagine as a standardized test system or systems in the future.
My usual process of this work involves drawing each of the key uncertainties and their poles on a whiteboard or large sheet of paper, and then looking for patterns. The patterns of narrative similarity usually appear during writing,. Those uncertainties that seem familiar can be grouped or clustered on the workspace. If patterns become apparent later, use lines to connect them.
These clusters then act as a secondary reflection of the vote, and provide further reason to maintain the breadth of overlapping concepts. Because people bring their own experience to the vote, someone voting for measurement from an assessment team might not vote for sources of learning. Similarly, a dean might vote for sources of learning or paths to learning over measurement, while a vocational instructor might lean to skills development. The clusters then act as super categories that increase the favorable strength of the underlying narrative that these uncertainties suggest.
The next step is hard to explain, but can be learned through experience: identifying uncertainties that will drive great, divergent stories. Consider these two attributes:
- The divergence of poles sets up the reasonable expectation that when the axes are crossed, the resulting quadrants will offer divergent narrative canvases.
- Interesting and inclusive ideas create the basis for a good story. For instance, students co-creating their learning experiences is a more interesting idea than classes taught either in a building or through the Internet. Although the ultimate way that learning is delivered hasn’t been determined, and might never be, the extremes, and their hybrids already exist in the market, so making location the major driving force for the scenarios isn’t that interesting. Co-creation of learning experiences offers a much richer canvas with many more possible story lines.
Creating the Candidate Matrices
As a rule of thumb, those uncertainties that end up clustered end up higher on the matrix axis candidate even if none of the individual items were ranked highest.
It is sometimes the case as well, that the highest ranked uncertainty doesn’t offer a good mix of divergence and story telling. Sometimes the uncertainty that ranks highest ends up being a little too close. In the case of the recent work at the University of Georgia, the “Funding Source” for education was the top vote getter. But this isn’t about the actual source of the funds, but the behavior and transparency of the funder. A funder who obscures their accounting versus one who is transparent and disciplined, isn’t a great axis for a project focused on the future of learning. It will provide some interesting color to the stories, but it would be imprudent to select it as a major axis.
The first matrix is usually derived from the largest cluster, and from that cluster, the biggest umbrella idea, the one that appears most able to encompass the other ideas.
In the case of the University of Georgia work, that involved a five-uncertainty cluster, with “Sources of Learning” acting as the largest concept among the cluster. The next cluster with good story telling potential was then selected. From this cluster, “pace of change,” was used as it offers a somewhat broader than that of “innovation” because it isn’t just about new, but about change and it includes a sense of time.
This yielded the following matrix:
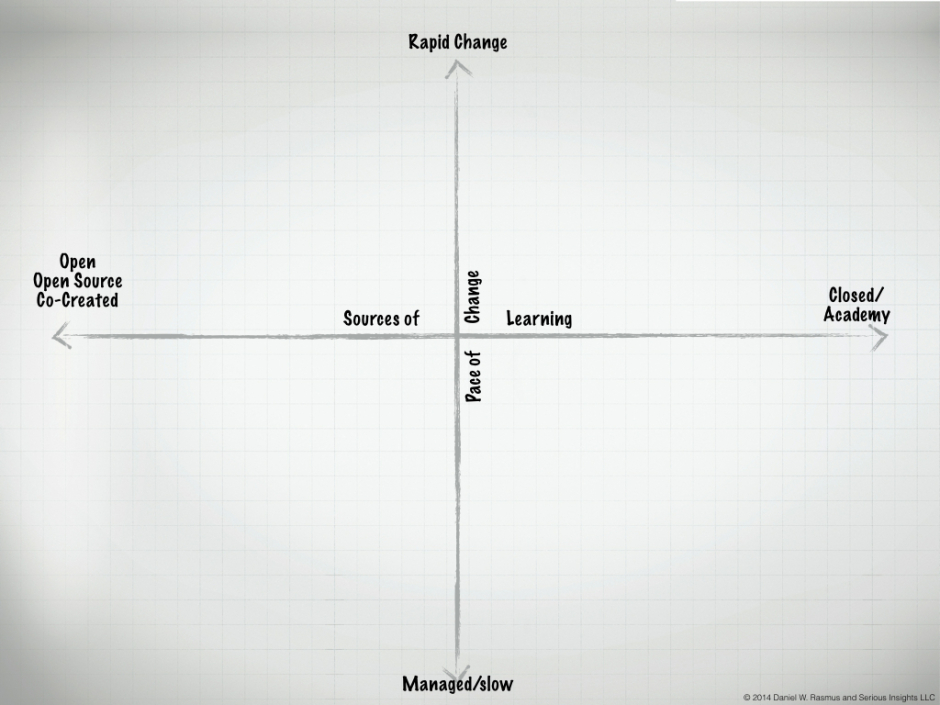
Using the heuristics stated above, three additional sets were created. A quick fitness test and a talking through the stories determined that these candidate sets were viable.
The other matrices look like this:

A Quick Fitness Test
The next step involves an analysis of the sets for usefulness. The quick fitness test involves looking at the following attributes of the matrix:
Does each quadrant end up with a BIG IDEA that could represent it in shorthand form?
Is the stated future of the organization somewhere to be seen in the matrix?
Do the futures feel related? For instance: Is it possible to imagine one future transforming into the other? It isn’t necessary to describe the logic for the transformation; a sense that such a transformation is possible is enough at this stage.
Note that this test will be applied more robustly later against the selected matrix, where participants will be asked to document the big idea, refine their “vision” in light of the scenarios and document the logic and the events that might transform one future into another.
Telling Stories To Yourself
The goal of creating sketches of the future is to provide just enough information that people looking at it can vote. Notes can include:
- Statements that demonstrate the divergence of an idea across the scenarios.
- Phases that hint at how good the scenario might be as a canvas for storytelling.
- Each scenario has a big idea that represents it.
Yes, that sounds like the quick fitness test, but that test takes place in the mind of the scenario planner as they are creating a set of sets. Once the set of sets is complete, the scenario planner or team needs to create just enough narrative that people looking at the scenarios can get a sense for which one might best serve the purposes of the project. The final step in this process, remember, is to vote on a single scenario set to develop.
Don’t go into great depth, just develop key words and phrases that hint at what each of the futures could expand into. There is plenty of work ahead to develop the scenario stories and the logic that drives them.
“As ideas arrive, jot them down on sticky notes or just on the paper itself. Don’t be afraid to second guess the initial answers, as they will evolve over time”
It is important to note that the moment the uncertainties cross, the scenario planner should place themselves at the center of the intersection, which is “the now.” During the selection phase, the planner should, rather than worry about the path, leap quickly to the ultimate expression of the two ideas within the context of the focal question, which ideally includes a temporal description. In the case of our example, “What does learning look like in 2030?” the far edge reflect speculation about what the world looks like in 2030 under the constraints imposed by the two uncertainties. That means that the ideas about the future jotted down in the quadrants are 2030 attribute values or ideas, not those from 2014.
And once properly oriented, the scenario planner (or team) starts talking to themselves. Quite literally talking to themselves, as this is often the best way to understand a futures quadrant quickly. As ideas arrive, jot them down on sticky notes or just on the paper itself (or on the computer). Don’t be afraid to second guess the initial answers, as they will evolve over time.
Timing
It is not advisable to dwell too long on the scenario sets before the vote. The longer researchers work with a set of the scenarios the more likely they are to analyze the shortcomings of these sets, reconfigure them and refine them, which is not a good use of times (or dollars for those investing in consultants). If a set of scenarios has been suggested, as note above, each of these is viable, then adding detail to sets that will eventually be abandoned doesn’t provide value.
In an ideal engagement, the entire process described here, from analyzing the highest ranked uncertainties to voting on the candidate matrices, should take no more than a couple of hours.
Developing deep stories, understanding causes and conducting additional research is best applied to the selected matrix.
Did We Get It Right?
For the team, right is pretty simple: you don’t care which of the candidate sets win. Since the selection criteria has been applied and only plausible and useful sets are presented back to the client, no matter which candidate set the team selects, storytelling and imagination will create useful futures for the exploration of the focal question and related issues.
Domain Specifics
The horizontal nature of scenario planning makes it difficult to codify heuristics for matrix creation. The technique can be applied to any domain, but the uncertainties and eventual scenarios are very domain specific. That means it is challenging to generalize about uncertainty selection for scenarios beyond what has been discussed because knowledge of the domain plays a role in understanding the potential narratives.
Good scenario planners have usually applied the technique to a wide range of problems and have picked up domain expertise along the way, which helps them develop and suggest viable candidates scenario sets.
The Vote
The last step in this process is the vote. The vote is very simple. People either view the sketches or have them presented to them. People vote on the one they feel best represents the focal question and the needs of the project.
Final Notes
Getting to a matrix requires a team effort. It is better done with at least a couple of experienced people than by one. It can also be an iterative process, taking into account different people’s lenses for categorization as they are exposed to the initial take.
